

Consider a scenario where we have to process messages only once. If there are any duplicates they should be skipped. In Apache Camel we can use the Idempotent Consumer to filter out duplicated messages, it essentially acts like a Message Filter to avoid duplications.
This is a very useful feature in the integration use cases. In order to achieve this Apache Camel keeps track of the consumed messages using a message id which is stored in the repository called Idempotent Repository.
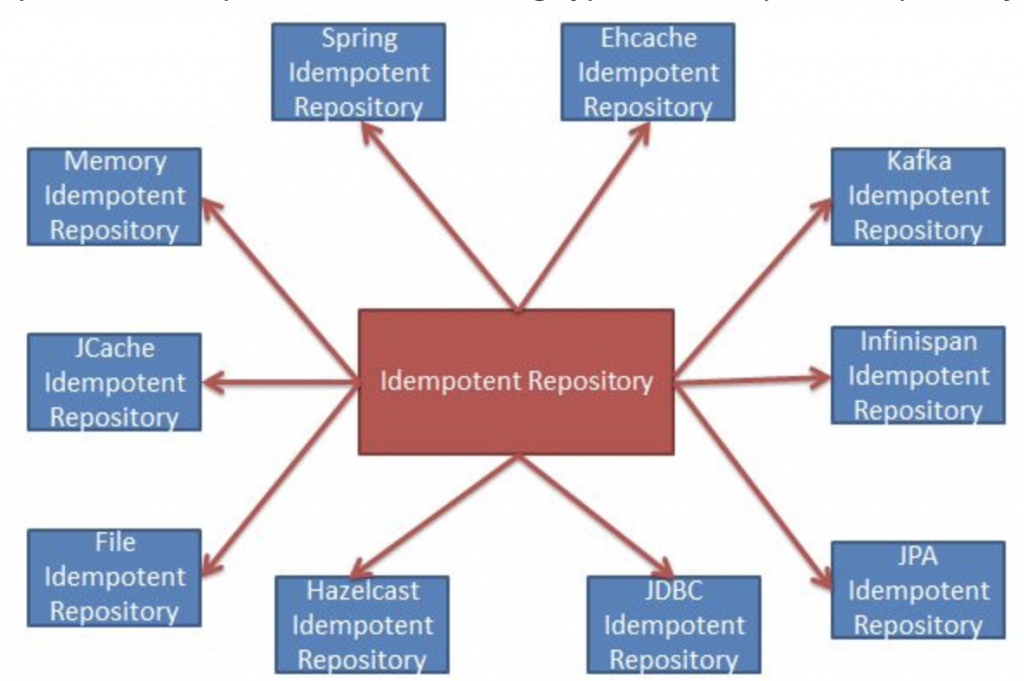
Apache Camel provides the following type of IdempotentRepository.
Implement message transfer using Apache Camel Kafka Component
From Apache Camel documentation the idempotent consumer works as follows: "Camel will add the message id eagerly to the repository to detect duplication also for Exchange's' currently in progress. On completion Camel will remove the message id from the repository if the Exchange failed, otherwise it stays there" . This means we will be able to ensure that your systems only process messages exactly once, that implies we will not ingest the same payload multiple times for example in a Kafka topic or in a database.
We will implement the next example:

In this article, we will do a step-by-step deployment using Kubernetes (k3d), Strimzi and Camel K.
We use mock data in a CSV file with duplicated registries as follows:
ORDERNUMBER,QUANTITYORDERED,PRICEEACH,SALES,ORDERDATE,STATUS,PRODUCTLINE
10107,30,95.7,2871,2/24/2003 0:00,Shipped,Motorcycles
10107,30,95.7,2871,2/24/2003 0:00,Shipped,Motorcycles
10107,30,95.7,2871,2/24/2003 0:00,Shipped,Motorcycles
10145,45,83.26,3746.7,8/25/2003 0:00,Shipped,Motorcycles
10145,45,83.26,3746.7,8/25/2003 0:00,Shipped,Motorcycles
...
10121,34,81.35,2765.9,5/7/2003 0:00,Shipped,Motorcycles
10121,34,81.35,2765.9,5/7/2003 0:00,Shipped,Motorcycles
10145,45,83.26,3746.7,8/25/2003 0:00,Shipped,Motorcycles
10180,29,86.13,2497.77,11/11/2003 0:00,Shipped,Motorcycles
10145,45,83.26,3746.7,8/25/2003 0:00,Shipped,MotorcyclesStep 1. Run local kubernetes.
k3d cluster create mycluster -p --registry-create k3d-mycluster-registry:5000Step 2. Clone the repository with configuration files.
git clone https://github.com/mikeintoch/camel-kafka-idempotent.gitStep 3. Create a namespace
kubectl create ns idempotentDeploy Strimzi Operator
Step 4. Deploy Strimzi in the namespace.
kubectl create -f 'https://strimzi.io/install/latest?namespace=idempotent' -n idempotentStep 5. Create Kafka cluster
kubectl apply -f camel-kafka-idempotent/assets/kafka-cluster-ephemeral.yaml -n idempotentDeploy Camel K Routes
Step 6. Deploy Camel K Operator
kamel install --force --olm=false -n idempotent --registry k3d-mycluster-registry:5000 --registry-insecure trueStep 7. Deploy Consumer Route
kamel run DataConsumer.java -n indempotentStep 8. Deploy Idempotent Consumer Route
kamel run IdempotentFilter.java -n idempotentWe will use KafkaIdempotentRepository to avoid duplicated messages, we have to configure the name of the topic and the broker where it will be available, also we will be filtering messages using ORDERNUMBER property.
// camel-k: language=java property-file=consumer.properties
// camel-k: dependency=camel:gson
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.model.dataformat.JsonLibrary;
import org.apache.camel.processor.idempotent.kafka.KafkaIdempotentRepository;
public class IdempotentFilter extends RouteBuilder {
@Override
public void configure() throws Exception {
//Configure Idempotent Repository
KafkaIdempotentRepository kafkaIdempotentRepository = new KafkaIdempotentRepository("idempotent-orders", "broker-kafka-bootstrap:9092");
from("kafka:duplicate-topic-data")
//unmarshal to manipulate message
.unmarshal().json(JsonLibrary.Gson)
// Configure Idempotent consumer
.idempotentConsumer(simple("${body[ORDERNUMBER]}"), kafkaIdempotentRepository)
//Process filter orders
.log("Order Sent: ${body[ORDERNUMBER]}")
//marshal again to sent kafka broker
.marshal().json(JsonLibrary.Gson)
.to("kafka:filtered-orders-data");
}
}Step 9. Deploy Data Producer Route.
kamel run DataProducer.java -n idempotentThis route gets the content in the csv file and sends it to kafka topic named duplicate-topic-data
Step 10. Verify the idempotent filter works correctly.
We can observe in the consumer logs, that it has received messages exactly once avoiding duplicated messages from the source.
kubectl logs -f <data-consumer-pod> -n idempotentKafkaConsumer[filtered-orders-data]) Order Received: 10107
KafkaConsumer[filtered-orders-data]) Order Received: 10121
KafkaConsumer[filtered-orders-data]) Order Received: 10134
KafkaConsumer[filtered-orders-data]) Order Received: 10145
KafkaConsumer[filtered-orders-data]) Order Received: 10159
KafkaConsumer[filtered-orders-data]) Order Received: 10168
KafkaConsumer[filtered-orders-data]) Order Received: 10180
KafkaConsumer[filtered-orders-data]) Order Received: 10188
KafkaConsumer[filtered-orders-data]) Order Received: 10201We made a simple example to know how to idempotent consumer works, there are many options to configure our consumer and for more information please visit: